分别编译
C++支持C语言中有关分别编译的概念。这种机制可以用于程序组织为一组部分独立的片段。
典型地,我们将描述一个模块的界面的声明放进一个文件里,以文件名表示它的正当使用方式。这样,
namespace Stack // 界面
{
void push(char);
char pop();
}
可能被放入文件stack.h,堆栈的用户将像下面这样包含该文件(这种文件称为头文件):
#include "stack.h" // 获得界面
void f()
{
Stack::push('c');
if(Stack::pop()!='c') error("impossible");
}
为了帮助编译器保证程序的一致性,提供了Stack模块实现的文件也要包含这个文件:
#include "stack.h" // 获得界面
namespace Stack
{
const int max_size = 200;
char v[max_size];
int top = 0;
}
void Stack::push(char c) { /* 检查上溢并压入c */ }
char Stack::pop() { /* 检查下溢并弹出 */ }
用户代码放在第三个文件里,例如位于user.c中。在stack.c和user.c中的代码共享stack.h提供的堆栈界面信息,除此之外这两个文件就是互不相关的,可以分别进行编译。这些程序片段可以用下面的图表示:
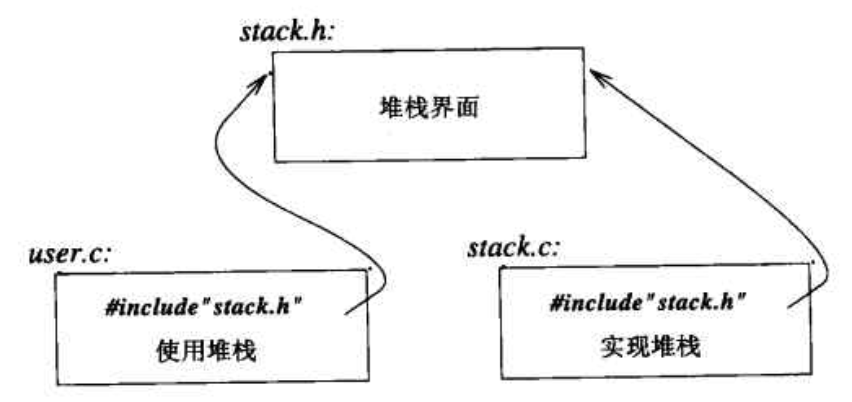
分别编译是一切实际程序中都需要考虑的问题。在程序里,不能简单地将所提供的功能,例如Stack,当做模块。严格地说,分别编译的使用并不是语言要考虑的问题,而是关于如何最好地利用特定语言实现的优点的问题。当然,在实践中这个问题是极其重要的。最好的方式就是最大限度地模块化,通过语言特征去逻辑地表示模块化,而后通过能最有效地分别编译的一组文件,物理地利用这种模块化机制。
🔚